
Artificial Intelligence (Künstliche Intelligenz), Machine Learning (Maschinelles Lernen) und Deep Learning sind in aller Munde. Lesen Sie in unserer dreiteiligen Serie, was die Begriffe unterscheidet, was sie eint und was Unternehmen verpassen, die sich nicht damit beschäftigen. Nachdem es im Teil 1 um den Oberbegriff Artificial Intelligence ging, beleuchten wir im heutigen Beitrag die Teildisziplinen Machine Learning und Deep Learning.
Machine Learning
Unter Machine Learning (= Maschinelles Lernen) wird allgemein die Generierung von Wissen auf Basis von Erfahrungswerten anhand von Beispielen und Mustern (=pattern) verstanden. Das System lernt, aus vorgegebenen Beispielen und auf der Basis von Gesetzmäßigkeiten eine Abstraktion zu erstellen, sodass nach Abschluss der Lernphase das Erlernte verallgemeinert und für die weitere Schlussfolgerung herangezogen werden kann. Dies ist mitunter auch für unbekannte Datensätze möglich.
Beim Maschinellen Lernen unterscheidet man grundsätzlich zwei Arten von Systemen: symbolische und subsymbolischen Systeme. Bei symbolischen Systemen sind die Trainingsbeispiele und das trainierte Wissen „explizit repräsentiert“, d.h. sie lassen sich mathematisch nachweisen oder sprachlich fassbar machen und direkt nachvollziehen. Symbolische Systeme bedienen sich der Aussagenlogik (z. B. Aussage: „Manfred ist ein Mensch“. Daraus folgt aber nicht unbedingt, dass nur Menschen Manfred heißen und schon gar nicht, dass alle Menschen Manfred heißen.) und einer Erweiterung derselben, der Prädikatenlogik, auf der Ontologien und das Semantic Web basieren. („Manfred“, Prädikat: „… ist ein Mensch“.)
Bei subsymbolischen Systemen ist zwar ein berechenbares Verhalten antrainiert, jedoch lässt sich das genaue Verhalten der Netze nicht vorhersagen und es ist kein direkter Einblick in die Lösungswege möglich. Man spricht hier von „implizit repräsentiert“. Eine Ausprägung subsymbolischer Systeme sind neuronale Netze, wie sie auch bei Deep Learning Anwendung finden.
Daneben gibt es unterschiedliche Wege, wie ein solches System trainiert werden kann. Man unterscheidet hier unter supervised Learning (überwachtes Lernen) und unsupervised Learning (unüberwachtes Lernen)
Supervised Learning
Beim supervised Learning wird anhand gegebener Eingaben mit den jeweils erwarteten Ausgabewerten das System trainiert. Das System lernt dabei durch den Eingriff eines Lehrers richtige Antworten kennen und überführt diese in Algorithmen. Als gutes Beispiel dient hier die Klassifizierung von Objekten. Dem System werden verschiedene Objekte präsentiert. Dies können beispielswese entweder „Autos“ oder „keine Autos“ sein. Ein Trainer / Lehrer führt nun eine Klassifizierung für eine Reihe von Beispielbildern durch. Es kann sich dabei um verschiedene Automodelle handeln, aber auch um beliebige andere Objekte, wie Fahrräder, Blumen, Häuser. Der Trainer teilt dem System nun mit, bei welchen Objekten es sich um Autos handelt und bei welchen nicht. Auf dieser Basis lernt das System die Charakteristika eines Autos kennen und kann diese im Vergleich bei neuen Objekten anwenden, um die Entscheidung zu treffen, ob es sich bei einem Objekt um ein Auto oder um kein Auto handelt.
Dieses einfache Beispiel lässt sich im nächsten Schritt erweitern, indem das System nun verschiedene Autohersteller oder konkrete Modelle lernt. Es wäre auch möglich, z. B. nur „grüne Autos“ zu identifizieren oder Kombis von Stufenhecklimousinen zu unterscheiden. Entscheidend ist, dass bei diesem Ansatz noch Einfluss von außen auf das System genommen wird.

Unsupervised Learning
Beim unsupervised Learning führt man dem System Bilder von Objekten als Trainingsdaten zu (in diesem Beispiel verschiedene Automobile). Auf Basis dieser Inputs erstellt das System vollautomatisiert ein Modell, das mit jedem weiteren Datensatz verfeinert wird. Das System lernt selber die Eigenschaften eines Autos zu extrahieren. Vom Ansatz her versucht es anhand sogenannter Features (Form, Anzahl der Räder, Länge, Breite, Höhe etc.) eine Segmentierung vorzunehmen, bis alle verfügbaren Bilder gemäß ihren Eigenschaften geclustert sind (klassisches Schubladendenken). Ein zusätzlicher Ansatz ist die Komprimierung von Informationen, indem „unwichtige“ Informationen weggelassen werden. Beispielsweise ist es für die Identifizierung von einem Automobil nicht unbedingt notwendig, die Farbinformationen zu erhalten, oder zu prüfen ob ein Scheibenwischer vorhanden ist, oder ob der Wagen die Typenbezeichnung am Heck angebracht hat. Das System lernt hier selbstständig, benötigt aber in der Regel sehr viele Daten, um eine sinnvolle Clusterung vornehmen zu können.

Machine Learning findet heute seine Anwendung z. B. in automatisierten Diagnoseverfahren, Aktienanalysen, Sprach- und Texterkennung sowie bei autonomen Systemen.
Ein weiteres Beispiel für den Einsatz von Machine Learning sind Recommendation Engines. Die persönlichen Empfehlungen bei Video on Demand Systemen, wie Netflix, Amazon Instant Video, ITunes, Videoload oder maxdome basieren auf Daten, die wir als Nutzer selbst generieren: a.) Welche Serie oder welcher Film wurde angesehen, b.) wie häufig wurde das Video angesehen, c.) wie schnell wurde die Serie / der Film geschaut, d.) wann wurden Pausen gemacht, e.) welche Filme / Serien wurden insgesamt angesehen und f.) welche Videos wurden ggf. abgebrochen. Die eigentliche Bewertung des Nutzers (bei Netflix: „Daumen hoch“ oder „Daumen runter“), die für ein spezifisches Video abgegeben wurde spielt dann bei der Auswertung keine übermäßige Rolle. Auf Basis der gesammelten Daten und dem Vergleich mit den Daten anderer Nutzer lassen sich Korrelationen bestimmen. Wenn man beispielsweise gerne „Road Trip Movies“ schaut und dazu gerne Dramen sieht, liegt eine Empfehlung für „Into the Wild“ nahe. Bei einem Nutzer, der eher Komödien mag, käme eine Empfehlung für „Wir sind die Millers“ oder „Harold & Kumar“ in Frage.
Weitere Details und umfangreiches, vor allem mathematisches Hintergrundwissen zu diesem Thema finden sich in: Introduction to Machine Learning, Nils J. Nilsson.
Deep Learning
Deep Learning (=tiefgehendes Lernen) ist ein Teilbereich des maschinellen Lernens und sicherlich der Aspekt der Künstlichen Intelligenz, der in den nächsten Jahren die meiste Aufmerksamkeit verdient. Interessanterweise sind die Ansätze des Deep Learning nicht wirklich neu. Die Grundlagen wurden bereits in den 50er Jahren des 19. Jahrhunderts gelegt, konnten jedoch aufgrund der damaligen Limitation in technischer und methodischer Hinsicht nicht weiterverfolgt werden.
Deep Learning beruht auf tiefen, vielschichtigen neuronalen Netzen (daher auch der Name) mit komplexer innerer Struktur, den sogenannten Hidden Layers. Dabei sind diese Netze dem menschlichen Gehirn nachempfunden und die Neuronen (Knotenpunkte) sind wie ein Netz miteinander verbunden, wie nachfolgend dargestellt.
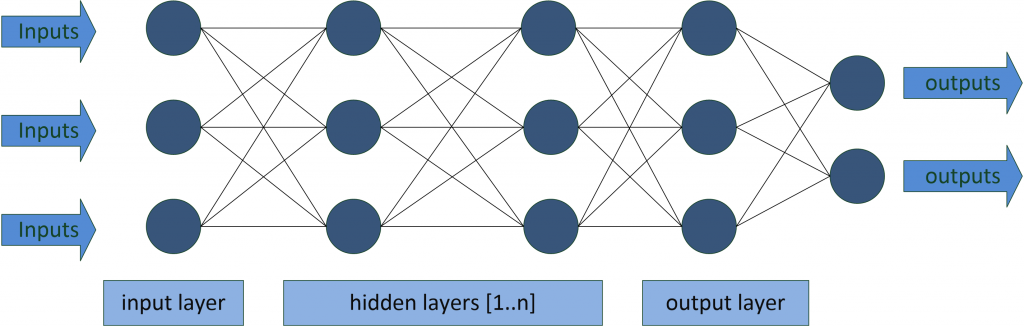
Charakteristisch für diese Art von Netzen ist, dass nur der Input- und Output-Layer nach außen sichtbar sind. Über die Inputs lassen sich Daten, Variablen und Parameter mitgeben; eine Sicht auf die sogenannten Hidden Layer ist nicht möglich. Die Rohdaten (z.B. die einzelnen Pixel eines Bildes) werden im Input Layer verarbeitet und dann an den nächsten Layer, den ersten Hidden Layer weitergegeben. Dabei werden mit jedem weiteren Hidden Layer Merkmale identifiziert und extrahiert, allerdings ohne dass diese vortrainiert werden müssen. Häufig finden hier sogenannte neuronale Faltungsnetzwerke (Convolutional Neural Networks) ihre Anwendung.
Bei der Erkennung von Objekten übernimmt nun jeder Hidden Layer eine spezifische Aufgabe. Im ersten Schritt könnte ein System zunächst verschiedene Filter anwenden um z. B. hell von dunkel zu unterscheiden, ein weiterer Layer könnte nach Farben segmentieren, dann Umrisse erkennen und im letzten Layer werden komplexe Formen erkannt. Jedes Neuron weist zusätzlich zu seiner Analyse dem Ergebnis noch eine Wahrscheinlichkeit zu, mit der es glaubt, das gestellte Problem gelöst zu haben. In dem vorherigen Beispiel der Klassifizierung eines Automobils könnte das System also nun wieder Farben, Form, Anzahl der Räder, Anzahl Türen, Anzahl und Form von Fenstern, Länge, Breite, Höhe oder beliebige andere Merkmale extrahieren. Nach der Analyse erstellt das System einen sogenannten Wahrscheinlichkeitsvektor mit einer prozentualen Wahrscheinlichkeit, zu dem es sich sicher ist, ein Auto erkannt zu haben.
Für ein sinnvolles Training von neuronalen Netzen und somit für die Anwendung von Deep Learning sind hoch performante Graphical Processing Units (GPUs), also klassische Grafikkarten, notwendig. Für die automatisierte Merkmalsextraktion und das Training sind je nach Anwendungszweck Tausende oder Millionen an Bildern notwendig. Dies lässt sich nur mit einer hohen Parallelisierung, wie sie aktuelle GPUs bieten, sinnvoll umsetzen.
Wer nun Lust bekommen hat, sich mit dem Thema neuronale Netzwerke näher auseinander zu setzen, kann erste Schritte auf der Webseite von Tensorflow unternehmen oder sich in Apache MXNet einlesen.
Im nächsten Blog-Beitrag zu diesem Thema stelle ich Amazon Sagemaker vor, ein Service bei dem jeder „everyday developer“ (O-Ton: re:Invent 2017) Deep Learning einsetzen kann.
Hier geht es zum dritten Teil der Blog-Reihe zu Artificial Intelligence.




