
Grundsätzlich gibt es viele Beweggründe, warum ein Unternehmen in die Cloud wechseln möchte. Neben Kostenersparnis der Total Cost of Ownership (TCO) spielen Aspekte wie Elastizität und Flexibilität, aber auch Innovationsdruck und Sicherheitsaspekte eine entscheidende Rolle. In diesem Artikel stellen wir das AWS Cloud Adoption Framework (CAF) vor, das auch beim Materna Cloud Readiness Checks eine wichtige Rolle einnimmt.
Den individuellen Weg in die Cloud strukturiert bestimmen
Der Weg in die Cloud ist für jede Organisation ein anderer und es ist wichtig, dass dieser strukturiert und umfassend geplant wird, um eine möglichst reibungsfreie Transition zu ermöglichen. Setzen Sie sich Ziele und erarbeiten Sie Abläufe für Ihren individuellen Weg in die Cloud. Neben den oftmals technischen Herausforderungen, die bei der tatsächlichen Migration zu lösen sind, spielen für eine holistische Betrachtung und bei der Planung der Cloud Journey weitere Aspekte eine entscheidende Rolle, um eine erfolgreiche Transformation zu einem “cloudifizierten” Unternehmen zu beschreiten. Auf Basis des AWS Cloud Adoption Framework, eingebettet in unseren Cloud Readiness Check, lässt sich hier die individuelle Roadmap planen. Dabei orientiert sich das CAF an allgemein anerkannten Best Practices und ist damit (weitestgehend) losgelöst von der angestrebten Cloud-Plattform einsetzbar.
Perspektiven und Schwerpunkte im Cloud Adoption Framework
Das CAF setzt sich aus sechs Perspektiven zusammen, die den umfangreichen Planungsvorgang in überschaubare Schwerpunktbereiche mit jeweils unterschiedlichen Zielgruppen und Verantwortlichkeiten aufteilen.
Dabei richten sich drei der Perspektiven an Beteiligte aus der IT und beleuchten somit die technische Basis: Plattform, Sicherheit und Betrieb. Die drei weiteren Perspektiven (Geschäft, Personen und Governance) decken die unternehmerischen Aspekte ab.Dazu kommt dann noch die Betrachtung des Reifegrades (Maturity), der im Februar 2017 in die anderen sechs Perspektiven integriert wurde.

People-Perspektive
Den Mittelpunkt bildet die Perspektive der Personen bzw. Mitarbeiter. Diese Perspektive beschäftigt sich mit der Personalentwicklung und -ausbildung im Cloud-Bereich. In diesem Bereich zu klärende Fragen sind z. B. „Wie können passende Teams zusammengestellt werden”, “Wie kann schnell Know-how aufgebaut werden?” und “Welche Skills bzw. Ausbildungen sind für welche Mitarbeiter(gruppen) sinnvoll?”.
Die People-Perspektive zeigt einen Weg hin zu einer agilen Organisation, die für eine effektive Cloud Transformation gut aufgestellt ist, und zu der oftmals umfassende organisatorische Änderungen notwendig sind. Es ist wichtig, in diesem Zuge die bestehenden Organisationsstrukturen zu prüfen, vorhandenen Skills und Prozesse zu evaluieren, Lücken aufzudecken und diese systematisch anzugehen.
Fangen Sie frühzeitig an, die Skills Ihrer Mitarbeiter zu trainieren, geben Sie Freiräume für die Cloud-Ausbildung (z. B. Besuch von Summits, Messen und Developer Days), lassen Sie Ihre Mitarbeiter einfach mal “Builders ” sein. Ein möglicher Ansatz für einen schnellen Skill-Aufbau ist die konsequente und regelmäßige Durchführung von Hackathons zu Cloud-Themen, wie Materna sie bereits seit mehreren Jahren durchführt.
Angesprochen bei diesem Schwerpunkt sind vor allem der Bereich Human Resources, Ressource Manager und Verantwortliche für die Ausbildung der Mitarbeiter.
Business-Perspektive
Die Geschäftsperspektive setzt den Schwerpunkt darauf, sicherzustellen, dass die IT-Entwicklung mit den Geschäftsanforderungen in Einklang gebracht wird und dass Investitionen im IT-Bereich und daraus resultierende Geschäftserfolge messbar und nachvollziehbar werden. Es ist wichtig, relevante Stakeholder aus dem Management von Anfang an bei der Cloud-Adoption mit einzubeziehen und gemeinsam einen tragfähigen Business Case auszuarbeiten. Hierbei müssen die IT und das Management eine gemeinsame Strategie entwickeln und die Cloud-Initiativen priorisieren. Wichtig ist es dabei, schnelle Erfolge (“quick wins”) zu verbuchen, indem sogenannte “low hanging fruits” identifiziert werden. Oder anders gesagt: Welcher Aspekt bzw. welche Applikation lässt sich mit verhältnismäßig geringem Aufwand in die Cloud bringen (Stichwort: “Lift & Shift ”), hat aber einen großen Nutzwert für das Unternehmen?
Angesprochen bei diesem Schwerpunkt sind vor allem: Management, Strategieentwickler und Budgetverwalter.
Governance-Perspektive
Die Führungsperspektive adressiert sowohl das Portfoliomanagement, das Programm- und Projektmanagement ebenso wie die Themen Lizenzmanagement und Geschäftsleistung.
Das Portfoliomanagement muss eruieren, mit welchen Mechanismen das Thema Cloud und eine Priorisierung auf die Verwendung von Cloud-Services im täglichen Business vorangetrieben werden kann. Ferner ist zu beantworten, wie sich strategische Portfolioelemente erarbeiten lassen, welche die neu etablierte Cloud-Strategie im Unternehmen unterstützen und fördern können.
Aus Sicht des Programm- und Projektmanagements ist ein Umdenken vom traditionellen Wasserfallmodell hin zu agilen Methoden notwendig, um mit der schnellen Entwicklung von Cloud-Dienstleistern mithalten zu können. Dabei gilt es, nicht nur das Team weiterzuentwickeln, sondern auch ein neues Mindset in den Führungsebenen zu etablieren.
Angesprochen bei diesem Schwerpunkt sind vor allem: Projektmanager, Portfoliomanager und Programmmanager.
Platform-Perspektive
Die Plattformsicht beinhaltet die Strukturierung und eine Sicht auf die verfügbaren Cloud-Architekturen, um darauf basierend mögliche Zielarchitekturen für die jeweiligen Applikationen im Detail zu beschreiben. Wünschenswert wäre es dabei, wenn sich gleiche Vorgehensweisen für verschiedene Applikationen erneut einsetzen lassen. Dabei sind sowohl mögliche Migrationspfade, aber auch die Entwicklung neuer Anwendungen von dieser Perspektive abgedeckt.
Dabei liegt der Schwerpunkt auf den Ressourcen:
- Compute: Hier geht es um die Modellierung und Bereitstellung benötigter Ressourcen wie Arbeitsspeicher oder CPUs für Unternehmensanwendungen. Der wichtigste Punkte ist, dass hier andere Skills notwendig sind als bei der Ausrüstung und Bewirtschaftung eines Rechenzentrums. Die bekannten Prozesse verlagern sich von einer “real world logistic” immer mehr zu virtuellen und vor allem vollständig automatisierten Prozessen.
- Network: Auch hier ist eine Transition der Denk- und Vorgehensweise in den Bereich der virtuellen Provisionierung notwendig. Natürlich lassen sich auch in der Cloud weiterhin Firewall Appliances in virtuellen Maschinen einsetzen, aber ein großer Teil der Konfiguration wird über Security Groups erfolgen. Wichtig beim Aufsetzen der Netzwerke: Gleichen Sie frühzeitig die AWS-Adressbereiche mit Ihrem Unternehmensnetzwerk ab, damit es nicht zu unliebsamen Überraschungen bei der Etablierung einer Direct Connect Verbindung zwischen AWS und Ihrem on premise Rechenzentrum kommt. Vermeiden Sie die Nutzung der “Default”-Netzwerke.
- Storage: Auch der Umgang und die Bereitstellung von Speicher muss in der Cloud neu durchdacht werden. Hier spielen wieder die Beschaffungswege (real vs. virtual logistics) aber auch die technische Handhabung eine Rolle. Die AWS Cloud-Speichertypen decken vielfältige Anwendungsfelder ab, von beliebig skalierbarem Speicher in mehreren Güteklassen (S3) über Blockspeicher für EC2-Instanzen (EBS) bis hin zu Archivspeicher (Glacier), der sehr kostengünstig ist, aber in der Regel nur langsame Zugriffsmöglichkeiten bietet. Machen Sie sich umfassende Gedanken dazu, wie Ihre Speicherstrategie in Zukunft aussehen soll. Möglich ist z. B. auch der Einsatz eines Storage Gateways, um die Vorteile einer on premise Lösung mit denen der Cloud zu kombinieren.
- Database: Verfügbare Datenbanken reichen von klassischen RDMS bis hin zu cloud-nativen Datenbanken. Von Oracle, MS SQLServer über PostgreSQL und MariaDB bis zu vollständig verwalteten Datenbanken wie Aurora, Amazon DynamoDB oder Neptune als Graphendatenbankservice gilt es hier die richtige Variante zu wählen. Unterstützend bei der Migration mit minimaler Ausfallzeit hilft hier der AWS Database Migration Service, der z. B. auch Oracle Datenbanken zu PostgreSQL migrieren kann.
Dazu gibt es noch die übergreifenden Bereiche System und Lösungsarchitektur und Anwendungsentwicklung. Mit der strategischen Cloud-Ausrichtung ändern sich auch die Anforderungen an die System- und Lösungsarchitekten. Mit Cloud nativen Services und unter Verwendung von virtuellen Komponenten (Netzwerke, Gateways, Speicher etc.) können komplette Architekturen (nachvollziehbar und repetierbar) in strukturierten Textdateien (JSON, YAML) beschrieben werden (s. AWS Cloud Formation ). Dieses Vorgehen, als Infrastructure as Code (IaC) bezeichnet, bildet mit eine Basis für die Einführung von DevOps in Ihrem Unternehmen. Dazu gehören dann aus Entwicklersicht noch Continuous Integration and Continuous Deployment (CI/CD), um eine agile Entwicklung sowie Bereitstellung von Anwendungen in der Cloud zu ermöglichen. Neben den genannten Aspekten gilt es in Zukunft auch immer mehr eine Abwägung zu treffen, inwieweit man von den Basiskomponenten wie Storage und Compute weitere Cloud-native Services in die Entwicklung einbezieht. Letztlich ist dies immer eine Kosten- / Nutzenrechnung.
Angesprochen bei diesem Schwerpunkt sind vor allem: Systemarchitekten, Lösungsarchitekten, Software-Architekten und Entwickler.
Security-Perspektive
“Security at AWS is job zero”, so steht es in dem Whitepaper zum CAF beschrieben. Bei AWS gilt das “Shared Responsibility Model ” – AWS gewährleistet die Sicherheit “von der Cloud” und der Kunde ist verantwortlich für die Sicherheit “in der Cloud”. Das generelle Modell und die damit verbundenen Verantwortlichkeiten sind in Abbildung 2 dargestellt.
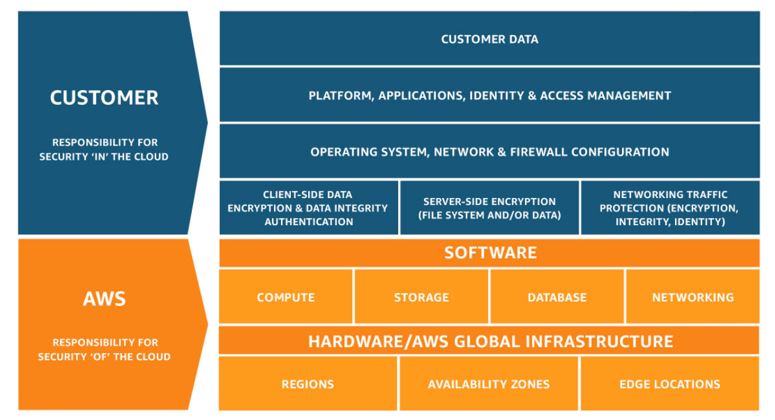
Je nach Typ des Services (PaaS oder IaaS) verschiebt sich der jeweilige Verantwortungsbereich gegebenenfalls noch. An relevanten Teilaspekten gilt es bei dieser Perspektive folgende Ausprägungen zu beachten
- Identity and Access Management: AWS bietet die Möglichkeit, z. B. auf Basis von Usern, Gruppen, Rollen und Policies feingranulare Rechte für Zugriffe auf Ressourcen und Daten festzulegen. Am besten legen Sie direkt nach Erstellung die Zugangsdaten zu Ihrem Root-Account in einen Tresor und arbeiten ausschließlich mit dedizierten Accounts mit eingeschränkten Rechten. Jemand, der Zugriff auf Ihren Root-Account hat, kann Ihre gesamte Infrastruktur manipulieren oder auch abschalten.
- Detective Control: Generell gibt es bei AWS ausgereifte Logging-Möglichkeiten für den Betrieb (Cloudwatch) und die nachvollziehbare Provisionierung von Ressourcen (CloudTrail), die nahe an Echtzeitbedürfnisse heranreichen. Aber letztlich geht es zumeist um die Korrelation verschiedener Ereignisse. AWS empfiehlt, die eigenen Logging-Dienste mit denen aus der Applikation und aus dem Betriebssystem zusammen zu bringen. Hier können oftmals auch externe Lösungen, wie z. B. Splunk (die sich auch in der Cloud betreiben lassen) eingesetzt werden, um aufschlussreiche Informationen im Fehlerfall zu liefern. Wichtig ist, dass es hier um die Sicherheit “in der Cloud”, also um den Verantwortungsbereich des Kunden, geht.
- Infrastructure Security: Da in der Cloud die Infrastruktur “atmen”, also sich den jeweiligen Bedürfnissen in Hinblick auf Workload und Geschäftsanforderungen jederzeit anpassen lässt, muss sich auch die Etablierung von Sicherheit für die Infrastruktur in einer agilen Art und Weise kontrollieren lassen. Es gilt hier auch möglichst den gesamten Prozess (build – deploy – operate) im Bereich der Security zu automatisieren.
- Data Protection: beschäftigt sich mit der Konfiguration von Sichtbarkeit und der Kontrolle über Daten. Wer hat Zugriff auf welche Daten? Welche Policies bzw. Rechte greifen? Sind diese Rechte so minimal wie notwendig festgelegt worden?
- Incident Response: Hier gilt es, geeignete Strategien zu etablieren, wie Sie in Ihrem Unternehmen mit Incidents umgehen, um ihre Auswirkungen zu reduzieren, in geeigneter Form zu kommunizieren und den Betrieb schnellstmöglich wieder herzustellen. Bei der Cloud-Adoption sollte abgewogen werden, ob der Fokus von Sicherheitsexperten von der direkten Reaktion auf Sicherheitsvorfälle nicht eher in Richtung Forensik und Fehleranalyse (root cause) gelegt werden sollte. Den Wiederaufbau der Umgebung wird man skriptgesteuert auch ohne diese gewährleisten können.
Angesprochen bei diesem Schwerpunkt sind vor allem: Sicherheitsexperten, aber auch (System- / Lösungs- und Software-) Architekten und Operations.
Operations-Perspektive
Dieser Schwerpunkt evaluiert den aktuellen Status des Betriebs im Unternehmen und definiert die notwendigen Schritte, um diesen “cloud ready” weiterzuentwickeln. Hierbei geht es darum, Operations in die Lage zu versetzen, IT Workloads in der Cloud zu planen, auszurollen, einzusetzen und zu betreiben und im Fall der Fälle auch wiederherzustellen.
Betrachtung finden dabei die Punkte:
- Service Monitoring: Mit dem Einsatz von Cloud-Technologien kann der Umgang mit Serviceausfällen weitestgehend automatisiert werden, resultierend in einer deutlich besseren Verfügbarkeit. Auch hier gilt wieder, dass für die Cloud Adoption intensiver Wissensaufbau betrieben werden muss, um die neuen Möglichkeiten. die die Cloud mit sich bringt (z. B. automatisches Re-deployment einer Applikation auf einer anderen EC2-Instanz bei Ausfall auf IaaS-Basis), im Operationsbereich zu trainieren.
- Application Performance Monitoring: Vorbei sind die Zeiten, in denen zu Projektbeginn einmal die Infrastruktur in Form von Servern (oder VMs) festgelegt und danach nie wieder geändert wurde. Es gilt über das permanente Monitoring der Auslastung von Systemen eine stetige Optimierung sowohl aus Kosten- aber auch aus Performancesicht herbei zu führen. Materna hat beispielsweise die Größe der Datenbankinstanz während der Durchführung eines Gewinnspiels eines Kunden mehrfach an die jeweiligen Bedürfnisse (lastgestützt, z. B. wenn TV-Werbung angekündigt war) angepasst und damit über einen Zeitraum von wenigen Wochen einen vierstelligen Betrag an Hosting-Kosten für den Kunden einsparen können.
- Resource Inventory Management: Im Bereich der Cloud reduziert sich das Hardware Asset Management der Umgang mit dem Hardware-Lebenszyklus sowie das Lizenzmanagement auf das minimal Notwendige. Datenbanken lassen sich z. B. inklusive passender Lizenz einfach nutzen und werden “on demand” abgerechnet.
- Release Management/Change Management: Dieser Punkt beschäftigt sich damit, einen neuen Weg zu etablieren – weg vom trägen, klassischen Release Management hin zu einem agilen Prozess, der auf CI / CD beruht und schnell und sicher neue Releases ausrollen aber auch wieder zurückrollen kann. Beispielsweise können bei einer Microservice-orientierten Architektur die einzelnen Entwicklungsteams ihren Teil der Anwendung unabhängig von den anderen Teams bauen, deployen und ggf. auch betreiben. Es gibt hier im DevOps-Bereich das schöne Sprichwort: “You built it, you run it”, das auch bei allen AWS-Services Anwendung findet.
- Reporting and Analytics: Beschäftigt sich mit der Festlegung von KPIs (service-level agreements [SLAs] und operational-level agreements [OLAs]) sowie der kontinuierlichen Analyse dieser und dem damit einhergehenden Reporting. Operations sollte sich mit den Vorteilen und neuen Möglichkeiten beschäftigen, die sich aus dem Einsatz der Cloud in diesem Bereich ergeben (können).
- Business Continuity / Disaster Recovery (BCDR): Viele der bestehenden (“klassischen”) Prozesse rund um BCDR ändern sich in der Cloud. Hier geht es um den stetigen Wissensaufbau und die Entwicklung von neuen Strategien, die sich aus den erweiterten Funktionen (z. B. Multi AZ Deployments bei Datenbanken, unterschiedliche Redundanzen bei S3, automatisierte Instanzbackups, Failover und automatisches Redeployment bei nicht verfügbaren EC2 Instanzen) der Cloud ergeben. Wenn tatsächlich eine vollständige Availability Zone ausfallen sollte, gibt es in der Region noch weitere Rechenzentren, oder aber der Betrieb lässt sich in einer anderen Region (teilweise automatisiert) wieder aufsetzen. Es gilt dabei, die Vorteile der Cloud auszunutzen und strategisch mit einzuplanen.
- IT Service Catalog: Welche Services soll Ihr Unternehmen erbringen? Welche SLAs verbergen sich dahinter? Hier gilt es, eine lose Verbindung zwischen gewünschten und in Zukunft einzusetzenden Services aus Sicht der IT, aber auch mit der Sicht des Portfoliomanagements, herzustellen.
Angesprochen bei diesem Schwerpunkt sind vor allem: Operations.
Fazit
Das Cloud Adoption Framework bzw. dessen grober Überblick in diesem Artikel zeigt anhand verschiedener Themen auf, wie eine Transformation zu einem cloudifizierten Unternehmen möglich ist. Im nächsten Schritt gilt es, die sechs skizzierten Perspektiven im Detail zu beleuchten und einen Vorgehensplan zu erarbeiten. In dem Dokument “Creating an Action Plan” finden Sie weitere konkrete Schritte mit denen Sie mit dem CAF direkt loslegen können. Gerne helfen auch wir Ihnen weiter und begleiten Sie bei Ihrem stressfreien Weg in die Cloud.
Alle Beiträge dieser Blog-Serie zum Thema Cloud:
Teil 1 Darf es etwas weniger sein – wie man in der Cloud Kosten sparen kann
Teil 2 Wege in die Cloud: Die 6 R’s der Cloud-Migration
Teil 3 Designermuster für Cloud-Systeme – Design Patterns
Teil 4 AWS Cloud Adaption Framework


