
Artificial Intelligence (Künstliche Intelligenz), Machine Learning (Maschinelles Lernen) und Deep Learning sind in aller Munde. Lesen Sie in unserer dreiteiligen Serie, was die Begriffe unterscheidet, was sie eint und was Unternehmen verpassen, die sich nicht damit beschäftigen.
In den beiden vorangegangenen Artikeln unserer dreiteiligen Serie habe ich die Begrifflichkeiten Artificial Intelligence sowie Machine und Deep Learning vorgestellt. Darauf aufbauend möchte ich in diesem dritten Teil aufzeigen, wie Deep Learning mit geringem Aufwand und eingeschränktem Wissen zum Hintergrund neuronaler Netzwerke eingesetzt werden kann. Dies erfolgt am Beispiel von Amazon SageMaker, einem Dienst, den Amazon auf der Entwicklerkonferenz re:Invent 2017 vorgestellt hat. Natürlich finden sich ähnliche Beispiele und Dienste auch bei anderen Anbietern, wie Google (Machine Learning Services ), Microsoft (AI Platform ) oder IBM (Watson ).
AWS bietet Full Managed Service
„Machine Learning is still too complicated for everyday developers.“ Mit diesen Worten begann Andy Jassy, CEO von Amazon Web Services, die Ankündigung von Amazon SageMaker. Aus Sicht von AWS ist der Einsatz von Machine Learning / Deep Learning heute noch zu kompliziert, um von normalen Entwicklern in Projekten eingesetzt zu werden. Oftmals schrecken die mathematischen Anforderungen und das fehlende Wissen zu neuronalen Netzen eher von einem Einsatz ab. Genau hier setzt AWS an und bietet einen Managed Service, mit dem sich Machine-Learning-Modelle einfach in Anwendungen integrieren lassen.
Die nachfolgende Grafik zeigt die vier notwendigen Schritte, um Modelle über Trainingsjobs zu trainieren und diese Modelle dann über einen Endpoint bereitzustellen, damit sie von anderen Diensten oder Applikationen eingebunden werden können.
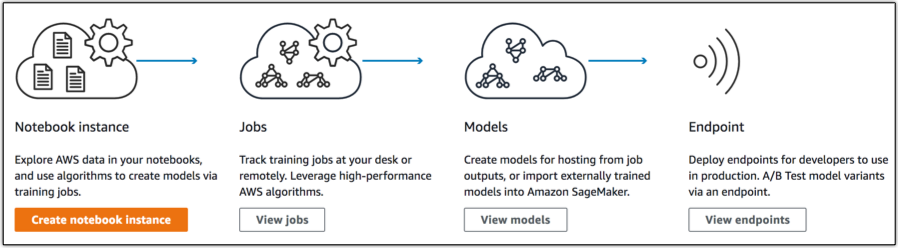
So lassen sich Netzwerke trainieren
Im nachfolgend aufgezeigten Beispiel wird ein simples Netzwerk auf Basis der Apache MXNet Module API trainiert. Das Netz wird aufgebaut aus Daten aus dem MNIST Datensatz mit handschriftlichen Zahlen von 0 – 9 (also 10 Klassen), die in Form von 70.000 Bildern vorliegen. Es handelt sich dabei um Graustufenbilder der Größe 28×28 Pixel. In unserem Beispiel wird der Datensatz in 60.000 Trainingsbilder und 10.000 weitere Bilder aufgeteilt, von denen einige nachfolgend exemplarisch dargestellt sind. Ziel ist es, das Netzwerk mit den 60.000 Bildern von Handschriften zu trainieren und das so trainierte Netzwerk im Anschluss weitere 10.000 Bilder klassifizieren zu lassen. Im Anschluss an das Training können dann beliebige handschriftliche Zahlen gegen das Netzwerk klassifiziert werden.

Im ersten Schritt wird in der AWS Console eine Notebook-Instanz gestartet, die dazu dient, das Netzwerk zu modellieren, mit Trainingsdaten zu versorgen und zu trainieren. Diese Instanz wird auch für die Bereitstellung des späteren Endpoints herangezogen. Bei der SageMaker Instanz wird ein passender Instanztyp gewählt sowie eine IAM Role generiert, die die Rechte der Instanz festlegt.
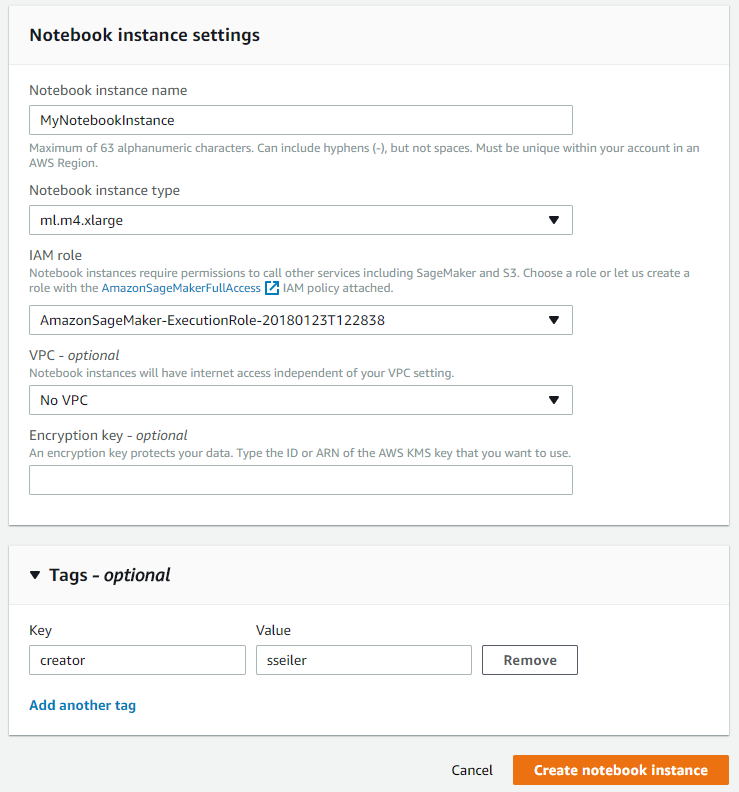
Nach dem Erstellen der Instanz (dies kann einige Minuten dauern) wird das Jupyter Notebook über „Notebook instances“, „Instanzname“, „Open“ gestartet.
Das nachfolgende Beispiel orientiert sich an dem Notebook „sample-notebooks/sagemaker-python-sdk/ mxnet_mnist“.
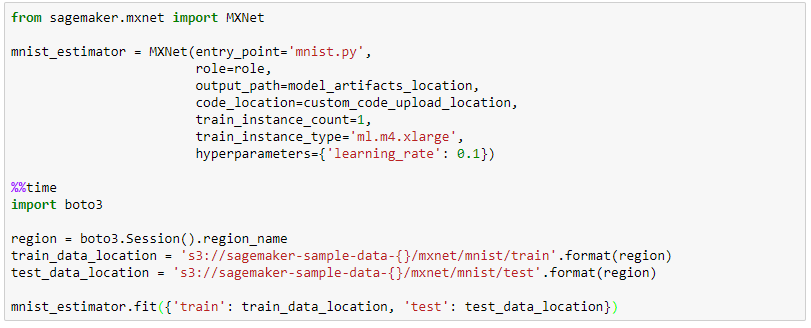
Zunächst wird die Python-Umgebung initialisiert und es werden die entsprechenden S3 Buckets (Dateiablageorte in AWS) definiert, in denen die Trainingsdaten und das spätere Modell abgelegt werden sollen.

Im nächsten Schritt wird über das AWS Sagemaker SDK die Funktion MXNet() mit diversen Parametern aufgerufen, u. a. dem Script „mnist.py“ als Entrypoint (das Script, das in dem Trainingsjob ausgeführt werden soll), aber auch den bereits definierten Ablageorten für die Daten, die Anzahl der zu verwendenden Instanzen und den gewünschten Instanztyp für die Ausführung. Über den Funktionsaufruf mnist_estimator.fit() wird der Job in SageMaker erstellt und die Trainings- und Testdatensätze übergeben. Der Job erscheint dann in der AWS Console.
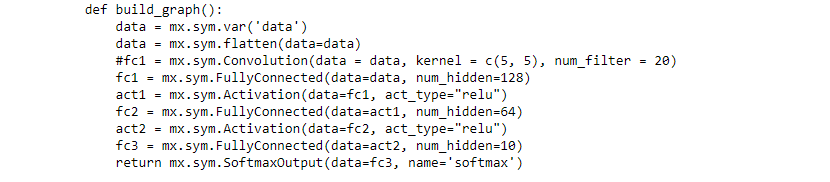
Das Modell nutzt diverse Layer aus dem MXNet Framework, die für das Training nacheinander abgearbeitet werden. Die nachfolgend gelisteten Funktionen sind für ein Training von Bilddaten, hier im Speziellen von Handschriften, gut geeignet:
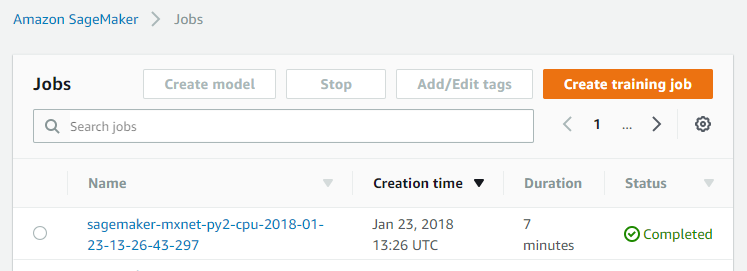
In dem untenstehenden Beispiel hat der Durchlauf des Trainings ca. sieben Minuten gedauert. Den aktuellen Status kann man während der Ausführung jederzeit einsehen.
Insgesamt wurden 25 Epochen (= Durchläufe) trainiert und nach jedem Durchlauf hat sich die Genauigkeit verbessert. Nach der ersten Epoche hatte das Netz eine Trainingsgenauigkeit von 23,49 Prozent und eine Validierungsgenauigkeit von 37,35 Prozent, zum Ende hin liegt die Trainingsgenauigkeit allerdings bei 99,87 Prozent und die Validierungsgenauigkeit bei 99,77 Prozent. Hier ein kurzer Ausschnitt der Konsolenausgabe:

Nach dem erfolgreich abgeschlossenen Training wechselt der Status auf „Completed“. Mit einem Klick auf den Job lassen sich im Fehlerfall die Logs („View Logs“) im Bereich „Monitor“ aufrufen, um mögliche Fehler zu analysieren.
Nachdem der Job erfolgreich beendet wurde, wird das Modell im nächsten Schritt über einen Endpoint bereitgestellt. Dieser ist dann über eine API direkt ansprechbar und kann Klassifizierungen auf Basis des trainierten Modells vornehmen. Über diese Funktion mnist_estimator.deploy lässt sich die Anzahl der Instanzen und deren Typ konfigurieren.

Im letzten Schritt werden nun handschriftliche Zahlen gegen das Netzwerk getestet. Die Ergebnisse können sich sehen lassen. Zahlen werden sehr zuverlässig erkannt. An dem Beispiel mit dem „M“ erkennt man aber auch, wo die Einschränkungen liegen. Das Netzwerk ist nicht darauf trainiert worden Buchstaben zu erkennen, also beherrscht es diese Aufgabe auch nicht.

Warum sollte man sich mit Machine Learning / Deep Learning auseinandersetzen?
Laut einer Studie von Crisp Research („Machine Learning im Unternehmenseinsatz “) beschäftigen sich heute bereits 64 Prozent aller Unternehmen mit Künstlicher Intelligenz. Mit Deep Learning befasst sich bereits jedes fünfte Unternehmen, wobei nur fünf Prozent Deep Learning bereits heute produktiv im Einsatz haben. Über 43 Prozent der Entscheider sind zudem überzeugt, dass es sich bei Machine Learning um kein reines Hype-Thema handelt, sondern sehen einen Wertschöpfungsanteil zwischen 11 und 50 Prozent (bis zum Jahr 2020) bei vernetzten Produkten und digitalen Services.
Einer der wichtigsten Gründe, sich mit Machine Learning zu beschäftigen, ist übrigens eine stärkere Kundenbindung.
Die Branchen Automotive, Konsumgüter sowie IT, Telekommunikation und Media sind Vorreiter und beschäftigen sich bereits intensiv mit Machine Learning. Die Branchen Chemie, Verkehr, Pharma und Logistik hinken noch etwas hinterher.
Machine Learning ist allerdings komplex und es gilt, zunächst den unterschiedlichen Methodenmix und die Algorithmen zu verstehen und zu evaluieren. Bei der Einführung sollten Unternehmen daher auf externe Beratung und professionelle Dienstleister zurückgreifen.


